| Zapewne tylko nieliczni wiedzą, że matematykę można z powodzeniem zastosować do datowania i analizy chronologii wydarzeń historycznych, opisanych w starych kronikach. Trudno w to uwierzyć, ale już od kilkudziesięciu lat istnieją metody matematyczno-statystyczne, które pozwalają to zrobić. Zostały one opracowane i wdrożone przez zespół rosyjskich matematyków (Kałasznikow, Fomenko, Nosowski, Raczew, Fedorow). Zaliczamy do nich takie specjalistyczne narzędzia, jak metodę rozpoznawania i datowania dynastii władców (tj. model małych zniekształceń dynastycznych), metodę porządkowania tekstów historycznych w czasie, model tłumienia częstotliwości, model dublowania częstotliwości (tj. wychwytywania duplikatów), metodę datowania wydarzeń, metodę ankiet-kodów (porównanie potoków biograficznych) i metodę korelacji lokalnych maksimów. Ostatnią z nich postaram się opisać niżej.
METODA KORELACJI AMPLITUD LOKALNYCH MAKSIMÓW (FUNKCJA POJEMNOŚCI TEKSTU HISTORYCZNEGO, KRONIKI ZALEŻNE I NIEZALEŻNE)
Załóżmy, że mamy do czynienia z tekstem X starej kroniki, opisującej nieznane nam wydarzenia z przedziału czasu (A,B), tj. między rokiem A i rokiem B. Daty wydarzeń mogą być podane według nieznanego nam klucza chronologicznego, na przykład są liczone poczynając od jakiegoś wydarzenia o znaczeniu regionalnym, np. od powstania miasta, od założenia dynastii, koronacji króla itp. Jest to datowanie WZGLĘDNE, w odróżnieniu od datowania ABSOLUTNEGO, wyrażanego liczbą lat przed naszą erą lub naszej ery. Czy i w jaki sposób można ustalić DATY ABSOLUTNE wydarzeń ze starego dokumentu? Na przykład jak wyznaczyć datę POWSTANIA MIASTA (patrz Tytus Liwiusz !!!), od której w dawnym dokumencie są liczone daty interesujących nas wydarzeń?
Jeśli niektóre z wydarzeń są nam znane z innych, prawidłowo datowanych kronik, wtedy możemy oczywiście, „podczepić” je do obowiązującej obecnie skali czasu. Ale takiego komfortu zazwyczaj nie mamy. Stary dokument równie dobrze może być napisany w innym języku, a kronikarz używa w nim całkiem innych imion, przydomków, nazw geograficznych itp., niż te, które są już nam znane. Bardzo często (o ile nie zawsze!) mamy też do czynienia z dokumentami mocno przeredagowanymi, bazującymi na pierwotnych oryginalnych tekstach, które bezpowrotnie zaginęły lub zostały zniszczone. Z całą pewnością metodyka o charakterze empiryczno-statystycznym, oparta na formalnej, ilościowej charakterystyce badanych tekstów, jest narzędziem analitycznym zdecydowanie bardziej obiektywnym, precyzyjnym, niezawodnym i efektywnym aniżeli subiektywna interpretacja starych tekstów.
Różnorodne charakterystyki pojemności informacji można tworzyć przez dokładne podliczenie:
1) vol X(t) - ilości stron w rozdziale X(t). Rodziałami nazwiemy tutaj mniejsze fragmenty tekstu, na które go rozłożymy, np. na poszczególne lata opisywane w kronice/annałach. Pojemność „rozdziału” X(t) może być zerowa, jeśli dany rok w kronice opuszczono. Zamiast ilości stron można podliczyć w tekście ilość akapitów, znaków itp.
2) ilości wzmianek o roku t w całej kronice X
3) ilości imion wszystkich historycznych postaci, wspomnianych w „rozdziale” X(t)
4) ilości wzmianek jakiegoś konkretnego imienia (osoby) w „rozdziale” X(t)
5) ilości odsyłaczy w „rozdziale” X(t) do jakiegoś innego tekstu.
Każda charakterystyka przypisuje do każdego opisanego w kronice roku t konkretną liczbę, a więc różnym latom będą odpowiadać różne liczby. Mówiąc ogólnie, poszczególne pojemności rozdziałów X(t) będą zmieniać się wraz ze zmianą numeracji (roku) t. Sekwencję pojemności X(A),…,X(B) nazwijmy funkcją pojemności danego tekstu X.
Odkładając na osi poziomej lata t, a na osi pionowej pojemności rozdziałów, tj. vol X(t), dla dwóch tekstów X i Y, opisujących ten sam okres czasu, otrzymamy przykładowo następujący wykres:
 rys.1 rys.1
Jak widać na rys.1, istotną cechą pojemności vol X(t) są lata t, w czasie których krzywa wykresu osiąga szczyt, tj. lokalne maksimum. Oznacza to, że rok, na który przypada taki szczyt (inaczej niż w innych latach, dla których wykres nie odnotowuje pików, tj. skoków przebiegu krzywej), musiał być przez kronikarza opisany bardziej szczegółowo, na przykład na większej ilości stron. Zresztą w różnych kronikach X i Y „szczegółowo opisanymi” mogą okazać się zupełnie różne lata. Może to być spowodowane tym, że kronikarz miał do wglądu większą ilość zachowanych do jego czasów materiałów źródłowych i informacji dotyczących danego roku albo z jakichś innych przyczyn (koniunkturalnych, propagandowych itp.) poświęcił opisowi danego roku znacznie więcej uwagi niż innym latom.
Kroniki historyczne X i Y, w przypadku których wierzchołki wykresów pokrywają się, można nazwać ZALEŻNYMI (patrz rys.1). Oznacza to, że opierają się one na tym samym pierwotnym źródle historycznym i opisują praktycznie te same wydarzenia w identycznym przedziale czasowym (A,B) z historii tego samego regionu geograficznego. Natomiast kroniki, które opisują wydarzenia z całkiem różnych przedziałów czasowych bądź różnych regionów geograficznych, nazwiemy NIEZALEŻNYMI. Zależność bądź niezależność kronik można ustalić porównując ich funkcje pojemności. Innymi słowy: punkty lokalnych maksimów na wykresach pojemności kronik zależnych będą ze sobą „korelować”, zaś w przypadku kronik niezależnych taka „korelacja” w ogóle nie będzie występowała. Przykład braku korelacji ilustruje poniższy wykres:
 rys.2 rys.2
Metody identyfikacji kronik zależnych i niezależnych okazały się dostatecznie efektywne przy porównywaniu kronik o mniej więcej jednakowej pojemności, lecz w przypadku kronik o zdecydowanie różnej pojemności sytuacja zaczyna się komplikować. Model korelacji lokalnych maksimów oparty jest na konkluzji, że różni kronikarze opisujący tę samą epokę historyczną posługiwali się zasadniczo tą samą pojemnością, tj. zbiorem ocalałej do ich czasów informacji. Jak wykazały eksperymenty, te lata, dla których zachowało się dużo tekstów, opisywali bardzo szczegółowo, a pozostałe lata - mniej szczegółowo.
Z biegiem czasu teksty pierwotne, napisane przez współczesnych - naocznych świadków wydarzeń - roku t, stopniowo ulegają zapomnieniu i utraceniu. Krzywa C(t) przedstawia obraz pierwotnego zbioru informacji, a krzywa C_M(t) to wykres późniejszego zbioru informacji, z których wiele zostało już utracone. Niech C(t) będzie pojemnością wszystkich dokumentów, napisanych przez ludzi żyjących w roku t, relacjonujących wydarzenia tego roku.
 rys.3 rys.3
Niech X i Y oznacza kronikarzy, pragnących napisać historię epoki (A,B), którzy nie są naocznymi świadkami wydarzeń tejże epoki, gdyż żyli w czasach późniejszych. Niech M (lub odpowiednio N) będzie rokiem, w którym kronikarz X (lub odpowiednio Y) opublikował kronikę epoki (A,B). C_M(t) to pojemność dokumentów, które ocalały z epoki (A,B) do chwili M, to znaczy do epoki, w której żył kronikarz X. Inaczej mówiąc, są to ostatki pierwotnych tekstów, zachowanych do czasu M. Wykres graficzny C_M(t) jest więc wykresem pojemności ocalałej informacji o wydarzeniach epoki (A,B). Analogicznie sprawa przedstawia się z wykresem C_N(t). Sedno modelu korelacji maksimów sprowadza się tutaj do spostrzeżenia, że każdy kronikarz X opisujący epokę (A,B) z reguły bardziej szczegółowo opisuje te lata, dla których wykres C_M(t) charakteryzuje się skokami przebiegu krzywej , tzn. im więcej dokumentów z epoki (A,B) doszło do kronikarza X, tym dokładniej i bardziej szczegółowo opisuje on ten czas:
 rys.4 rys.4
"Ubogie" i "bogate" kroniki i zakresy kronik: różnice między ubogimi a bogatymi kronikami można intuicyjnie rozpoznać na następującym wykresie:
 rys.5 rys.5
Ubogimi kronikami są takie kroniki, w których „większość” zakresów pojemności vol X(t) jest zerowa, tzn. większości lat kronikarz w ogóle nie opisał. Bogatą kroniką natomiast nazwiemy taką kronikę, w której przeciwnie „większość” zakresów pojemności vol X(t) jest różna od zera, czyli kronikarz przekazuje dużo wiadomości o wydarzeniach z epoki (A,B). Oczywiście w realnych warunkach trudno jest jednoznacznie zakwalifikować tę czy inną kronikę do ubogich lub bogatych. Z tego powodu wprowadzono pojęcia ubogich i bogatych stref w kronice, co zostało zilustrowane na rys.6:
 rys.6 rys.6
Oczywiście zdarzają się też sytuacje, w których biedna strefa może być usytuowana „w środku”:
 rys.7 rys.7
Istotne i nieistotne zera funkcji pojemności. Przy analizowaniu konkretnej kroniki zamiast skrajnego lewego punktu A na osi czasu, za punkt wyjścia bierzemy pierwszy rok, dla którego vol X(A) jest różny od zera, co znaczy, że rok ten został opisany przez kronikarza. Zero wykresu pojemności nazwiemy istotnym wtedy, gdy jest ono usytuowane na prawo od pierwszej niezerowej wartości wykresu. Patrz rys.8:
 rys.8 rys.8
Jeśli zero znajduje się na lewo od pierwszej niezerowej wartości, wówczas nazwiemy je nieistotnym. Nieistotne zero wskazuje na to, że kronikarz nie dość, że nic nie wie o danym roku, to w ogóle nie wie nic o wszystkich pozostałych latach ów rok poprzedzających. Zero istotne wskazuje na to, że wprawdzie kronikarz nic nie wie o danym roku, to jednak coś tam wie o latach, które ów rok poprzedzają.
Rozpatrzmy dowolną epokę historyczną (A,B) i kronikarza X, żyjącego w roku M, gdzie M jest dużo większe od B. Patrz rys.9:
 rys.9 rys.9
Kronikarz X, opisując wydarzenia epoki (A,B) jest zmuszony bazować na zbiorze ocalałej informacji C_M(t), który zachował się do jego czasów. Kronikarz w różny sposób podchodzi do ubogich i bogatych stref zasobu ocalonej informacji. Spostrzeżenie to pozwala sformułować następujący model oceny informacji: poszanowanie przez kronikarza ocalałej informacji jest odwrotnie proporcjonalne do jej pojemności. Spróbujmy to krótko wyjaśnić. Jeśli jakaś informacja zachowała się w „zerowym zbiorze”, to gdzieś po lewej i prawej stronie w jego otoczeniu znajdują się lata, o których kronikarzowi kompletnie nic nie wiadomo i kronikarz jest zmuszony szanować owe rzadkie, cudem zachowane do jego czasów wiadomości. Dlatego będzie je kopiował raczej sumiennie, wręcz niezależnie od osobistego stosunku do ich treści. Poza tym w ubogiej strefie zasobu ocalonej informacji kronikarz właściwie to nie ma tu „z czego wybierać”. Ewentualna arbitralność w jego podejściu jest siłą rzeczy jakby ograniczona znikomą pojemnością ocalonych informacji. W konsekwencji kronikarz dostatecznie sumiennie „odtwarza” amplitudy funkcji pojemności ocalonej informacji C_M(t) w obrębie ubogich stref. Natomiast w obrębie bogatych stref sytuacja przedstawia się odwrotnie. Tutaj kronikarz spotyka się z koniecznością dokonania selekcji potrzebnej mu informacji spośród dużego i często zbytecznego zasobu wiadomości. Im większy zasób ocalonej informacji, tym mniej kronikarz szanuje jego oddzielne fragmenty. Jak wykazały przeprowadzone eksperymenty, często przyczynia się to do tłumienia amplitud wykresów pojemności ocalonego zasobu w obrębie bogatych stref. W tym przypadku kronikarz może dać upust swym osobistym preferencjom, czyli wybierać sobie jedne informacje, a inne świadomie ignorować i pomijać.
Model amplitudowej korelacji wykresów pojemności w ubogich strefach kronik. Wyciągnijmy wnioski z modelu poszanowania informacji: Załóżmy, że dwóch kronikarzy X i Y opisuje te same wydarzenia, dziejące się w tym samym przedziale czasu (A,B). Każdy z nich dostatecznie dobrze kopiuje wykres pojemności ubogich stref zasobu ocalonych informacji o zdarzeniach epoki (A,B). W konsekwencji wykresy pojemności kroniki X i pojemności kroniki Y będą podobne w obrębie ubogich stref. Wywiedziona z tego prawidłowość statystyczna nosi nazwę modelu amplitudowej korelacji w ubogich strefach.
Podsumujmy:
a) jeśli kroniki X i Y są zależne, czyli opisują identyczne wydarzenia i czerpią ze wspólnego oryginalnego źródła, wówczas wykresy ich pojemności vol X(t) i vol Y(t) powinny dobrze korelować w obrębie ich ubogich stref. Równocześnie w obrębie ich bogatych stref może nie istnieć amplitudowa korelacja (po nałożeniu wykresów).
b) jeśli kroniki X i Y są niezależne, to wykresy ich pojemności w obrębie ich ubogich stref powinny być także niezależne, czyli amplitudowa korelacja (po nałożeniu wykresów) nie powinna istnieć.
Zatem w przypadku ubogich, zależnych kronik powinny korelować ze sobą nie tylko wierzchołki krzywych porównywanych wykresów, ale także ich amplitudy.
Opis modelu statystycznego i formalizacja. Rozpatrzmy przedział czasu (A,B) i wprowadźmy do niego współrzędną x, zmieniającą się od 0 do B-A, gdzie B-A to długość interesującego nas odcinka czasu. Zrozumiałe, że x=t-A. Niech f(x)=vol X(x) będzie funkcją pojemności kroniki X. Jako G(x) oznaczmy funkcję G(x)=f(0)+f(1)+...+f(x), to znaczy „przedział” funkcji f od 0 do x. Nazwijmy tę funkcję skumulowaną sumą kroniki X. Rozpatrzmy standaryzowaną skumulowaną sumę F(x) = G(x)/vol X, gdzie vol X to całkowita pojemność kroniki. Standaryzowana skumulowana suma jest wyrażona wykresem niemalejącym, którego wartości rosną od 0 do 1. Dla różnych kronik charakter tego wzrostu będzie różny. Rozpatrzmy nową funkcję g(x)=1-F(x), patrz rys.10:
 rys.10 rys.10
Jak widać z wykresu, wartości tej funkcji nie rosną. Nie wdając się zanadto w szczegóły, sformułujmy następujący model: funkcja g(x)=1-F(x) powinna zachowywać się w ubogiej, początkowej strefie kroniki jak funkcja exp(-(lambda) x^(alfa) ). W statystyce matematycznej tego rodzaju rozkłady nazywamy rozkładami Weibulla-Gnedenko. Jak widać, dysponujemy dwoma stopniami swobody: parametrem lambda i parametrem alfa, zmieniając które spróbujemy aproksymować funkcję 1-F(x). Jeśli uda się to zrobić dla konkretnych kronik, będzie to równoznaczne z potwierdzeniem modelu teoretycznego. Przeprowadzone na realnych kronikach eksperymenty statystyczne faktycznie wykazały, iż tłumienie wykresu 1-F(x) dostatecznie dobrze aproksymuje funkcję exp(-(lambda) x^(alpha) ) przy odpowiednim doborze wartości lambda i alfa. W rezultacie każdej kronice, a dokładniej mówiąc, początkowej ubogiej strefie kroniki możemy przyporządkować dwie liczby, wyrażające charakter zachowania funkcji pojemności kroniki. Nazwijmy lambda parametrem pojemności kroniki, a alfa parametrem formy kroniki. Najważniejszy dla nas jest parametr alfa. Jak wykazały eksperymenty statystyczne, to właśnie on najlepiej czuje charakter rozkładu oddzielnych, rzadkich pików wykresu pojemności w obrębie ubogiej strefy kroniki. To przede wszystkim parametr alfa będzie wskazywał, czy kroniki są zależne czy niezależne, natomiast parametr lambda jest bardziej odpowiedzialny za pojemność kroniki i wyczuwa, w jakim stopniu kronika jest uboga lub bogata.
Powyższą hipotezę, model statystyczny, można przeformułować w następujący sposób:
a) jeżeli kroniki X i Y są zależne, to odpowiadające im pary parametrów (alpha_X, lambda_X) i (alpha_Y, lambda_Y) powinny być bliskie, pod warunkiem, że zostały wyliczone dla ubogich stref kronik.
a) jeżeli zaś kroniki X i Y są niezależne, to odpowiadające im pary parametrów (alpha_X, lambda_X) i (alpha_Y, lambda_Y) powinny być „oddalone od siebie”.
Wygodnie jest przedstawiać parę liczb (alfa, lambda) jako punkt na zwykłej płaszczyźnie w układzie współrzędnych kartezjańskich alfa i lambda, patrz rys.11:
 rys.11 rys.11
Wzrost parametru "formy" kroniki wraz z upływem czasu.
Przy bliższej analizie dwóch różnych epok, jednej z ubogim początkowym zbiorem informacji, a drugiej z bogatym początkowym zbiorem informacji, można matematycznie wykazać, że wartość parametru alfa w pierwszym ubogim przypadku jest mniejsza niż wartość parametru alfa w drugim bogatym przypadku. Inaczej mówiąc, ubogie pierwotne zbiory charakteryzuje niska wartośc alfa, natomiast bogate pierwotne zbiory – wysoka wartość alfa. Tak więc im bliższa naszym czasom jest epoka historyczna (A,B), tym lepiej będą zachowane pierwotne zbiory informacji, czyli gdy na osi odciętych będziemy przemieszczać z lewej strony w prawą stronę, tj. bliżej do nas, odcinek czasu (A,B), wtedy średnia wartość parametru alfa będzie wzrastać.
Przejdźmy do bardziej dokładnego opisu modelu statystycznego i oceńmy, w jakim stopniu dwa wykresy jednocześnie robią skoki - narzędzia statystystyczne pozwalają nam określić parametr p(X,Y), mierzący rozbieżność lat szczegółowo opisanych w kronice X i lat szczegółowo opisanych w kronice Y. Traktując obserwowaną bliskość pików (skoków krzywej) na obu wykresach jako zdarzenie losowe, można liczbę p(X,Y) rozpatrywać jako prawdopodobieństwo tego zdarzenia. Im liczba ta jest mniejsza, tym lata szczegółowo opisane w X lepiej pokrywają się z latami szczegółowo opisanymi w Y. Do celów matematycznej definicji parametru p(X,Y) weźmy przedział czasu (A,B) i wykres pojemności vol X(t), który osiąga lokalne maksima w określonych punktach m_1,...,m_n-1. Dla większego uproszczenia można przyjąć, że każde lokalne maksimum jest odwzorowane równo w jednym punkcie. Te punkty, czyli lata m_i, dzielą przedział (A,B) na określone odcinki różnej długości. Patrz rys.12:
 rys.12 rys.12
Mierząc długości otrzymanych odcinków w latach, tj. mierząc odległości między punktami sąsiednich lokalnych maksimów m_i i m_i+1 otrzymamy sekwencję liczb całkowitych a(X)=(x_1,...,x_n). Liczba x_1 oznacza tutaj odległość między punktem A i pierwszym lokalnym maksimum, liczba x_2 oznacza odległość między pierwszym i drugim lokalnym maksimum. Liczba x_n to odległość między ostatnim lokalnym maksimum m_n-1 i punktem B. Tą sekwencję można opisać wektorem a(X) w przestrzeni euklidesowej R^n wymiaru n. I tak przykładowo przy zaistnieniu dwóch lokalnych maksimów, tzn. wtedy, gdy n=3, otrzymamy wektor całkowitoliczbowy a(X)=(x_1,x_2,x_3) w trójwymiarowej przestrzeni. Nazwijmy wektor a(X)=(x_1,x_2,x_3) wektorem lokalnych maksimów kroniki X. Dla drugiej kroniki Y będziemy mieli inny wektor a(Y)=(y_1,...,y_m). Przyjmujemy, że kronika Y opisuje wydarzenia w przedziale czasu (C,D), którego długość jest równa długości (A,B), tzn. B-A=D-C. By porównać wykresy pojemności kronik X i Y połączmy dwa odcinki czasowe (A,B) i (C,D) o jednakowej długości, nakładając je na siebie. Bez uszczerbku dla całości można uznać, że liczba maksimów jest jednakowa i dlatego wektory a(X) i a(Y) dwóch porównywanych kronik X i Y posiadają jednakową liczbę współrzędnych. Jeśli jednak liczba maksimów dwóch porównywanych wykresów byłaby różna, to można przyjąć, że niektóre maksima są krotne, tzn. w jednym punkcie zostało skomasowanych kilka lokalnych maksimów. Zarazem długości odpowiednich odcinków, które odpowiadają maksimom krotnym , można uznać za równe zeru. Wprawdzie wariant wprowadzenia maksimów krotnych jest niejednoznaczny, jednak dzięki niemu wstępnie można wyrównywać liczbę lokalnych maksimów na wykresach pojemności kronik X i Y. W dalszym postępowaniu można oczywiście pozbyć się tej niejednoznaczności, minimalizując niezbędne współczynniki bliskości wszelkimi możliwymi sposobami wprowadzenia maksimów krotnych. Warto zauważyć, że wprowadzenie maksimów krotnych oznacza, że w wektorze a(X) w niektórych miejscach pojawią się zerowe komponenty, czyli odcinki o zerowej długości. Tak więc porównując kroniki X i Y można uznać, że oba wektory a(X)=(x_1,...,x_n) i a(Y)=(y_1,...,y_n) mają tę samą liczbę współrzędnych i dlatego zawierają się w tej samej przestrzeni euklidesowej R^n. Zauważmy, że u każdego z tych wektorów suma jego współrzędnych jest jednakowa i równa się B-A=D-C, tj. długości przedziału czasu (A,B). Tak więc: x_1 + ... + x_n = y_1 + ... + y_n = B-A.
Rozpatrzmy teraz zbiór wszystkich wektorów całkowitoliczbowych c=(c_1,...,c_n), u których wszystkie współrzędne są nieujemne, a ich suma c_1+...+c_n jest równa tej samej liczbie, a mianowicie B-A, czyli długości przedziału czasowego (A,B). Oznaczmy zbiór wszystkich takich wektorów jako S. Wektory te można wyobrazić sobie geometrycznie w taki sposób, że wszystkie mają początek we współrzędnych, tzn. w punkcie O przestrzeni R^n. Końce wszystkich wektorów c=(c_1,...,c_n) znajdują się w „wielowymiarowym sympleksie” L, określonym w przestrzeni R^n jednym równaniem c_1 + ... + c_n = B-A, gdzie wszystkie współrzędne c_1,...,c_n są liczbami rzeczywistymi nieujemnymi. Zbiór S pod względem geometrycznym jest zbiorem „całych punktów” na sympleksie L, tzn. zbiorem wszystkich punktów z L, posiadających współrzędne całkowitoliczbowe. Tak więc końce wektorów lokalnych maksimów a(X) i a(Y) dla kronik X i Y należą do zbioru S. Patrz rys.13:
 rys.13 rys.13
Ustalmy teraz wektor a(X)=(x_1,...,x_n) i rozpatrzmy wszystkie wektory c=(c_1,...,c_n) z rzeczywistymi współrzędnymi, należące do sympleksu L i spełniające jeszcze jeden dodatkowy warunek:
(c_1 - x_1)^2 + ... + (c_n - x_n)^2 < (y_1 - x_1)^2 + ... + (y_n - x_n)^2.
Zbiór wszystkich takich wektorów c=(c_1,...,c_n) oznaczamy mianem K. Matematycznie można te wektory opisać jako oddalone od ustalonego wektora a(X) na odległość nie przekraczającą odległości r(X,Y) między wektorem a(X) i wektorem a(Y). Mówiąc o odległości między wektorami, mamy na myśli odległość między ich końcami. Zwróćmy uwagę, że wielkość (y_1 - x_1)^2 + ... + (y_n - x_n)^2 jest równa kwadratowi odległości r(X,Y) między wektorami a(X) i a(Y). Dlatego więc zbiór K to część sympleksu L, wchodzacy w "n-wymiarową" kulę o promieniu r(X,Y) ze środkiem w punkcie a(X).
Podliczmy, ile „całkowitoliczbowych wektorów” jest zawartych w zbiorze K, a ile w zbiorze L. Otrzymane liczby oznaczmy odpowiednio jako m(K) i m(L). Jako "predefiniowany współczynnik" p'(X,Y) weźmy stosunek obu tych liczb, to znaczy: p'(X,Y)=m(K)/m(L), czyli
liczba "całych punktów" w zbiorze K
p'(X,Y)= -----------------------------------------------
liczba "całych punktów" w zbiorze L
Zwróćmy szczególną uwagę na interpretację parametru liczbowego p'(X,Y). Jeśli założymy, że wektor c=(c_1,...,c_n) zupełnie przypadkowo „przebiega” wszystkie wektory ze zbioru S, a przy tym z jednakowym prawdopodobieństwem może znaleźć się w dowolnym punkcie tego zbioru, to mówimy, że wektor losowy c=(c_1,...,c_n) ma rozkład równomierny na zbiorze S, tzn. na zbiorze „całych punktów” (n-1)-wymiarowego sympleksu L. W takiej sytuacji liczba p'(X,Y) jest interpretowana jako prawdopodobieństwo. Jest ona równa prawdopodobieństwu zdarzenia losowego polegającego na tym, że wektor losowy c=(c_1,...,c_n) znajdzie się w odległości od ustalonego wektora a(X) nie większej jak odległość między wektorami a(X) i a(Y). Im mniejsze to prawdopodobieństwo, tym mniej przypadkowa rozpatrywana przez nas bliskość wektorów a(X) i a(Y). Inaczej mówiąc, ich bliskość wskazuje na istnienie pewnej zależności między nimi. Ponadto zależność ta jest tym większa, im mniejsza wartość parametru p'(X,Y).
Równomierność rozkładu wektora losowego c=(c_1,...,c_n) na sympleksie L, a dokładniej mówiąc, na zbiorze S jego „całych punktów”, może być spowodowana tym, że wektor ten odwzorowuje odległości między sąsiednimi lokalnymi maksimami funkcji pojemności „rozdziałów” kronik historycznych i innych analogicznych tekstów, opisujących zadany okres czasu (A,B). Rozpatrując wszelkie możliwe kroniki wydaje się oczywiste, że lokalne maksimum może „z równym prawdopodobieństwem” pojawiać się w dowolnym punkcie przedziału czasowego (A,B). Wcześniej było przyjęte założenie z wariantem wprowadzenia maksimów krotnych na wykresach pojemności kronik. Rozpatrzmy wszystkie takie warianty i obiczmy dla każdego z nich przypisaną mu liczbę p'(X,Y), a następnie weźmy najmniejszą z otrzymanych w ten sposób liczb. Oznaczmy tę liczbę jako p''(X,Y). To znaczy, teraz minimalizujemy parametr p'(X,Y) wszelkimi możliwymi sposobami wprowadzenia lokalnych maksimów na wykresach vol X(t) i vol Y(t). Po wykonaniu obliczeń dla parametru p''(X,Y) okazało się, że kroniki X i Y znajdują się w niepełnoprawnym położeniu. Rzecz polega na tym, że powyżej rozpatrywano ”n-wymiarową kulę” o promieniu r(X,Y) ze środkiem w punkcie a(X). Aby zlikwidować zaistniałą nierównoprawność między kronikami X i Y, zamienimy je po prostu miejscami i powtórzymy cała wyżej opisaną procedurę, przyjmując środek „n-wymiarowej kuli” w punkcie a(Y). Otrzymamy wówczas pewną liczbę, którą oznaczymy jako p''(Y,X). Zamiast „symetrycznego współczynnika” p(X,Y) weźmiemy średnią arytmetyczną z liczb p''(X,Y) i p''(Y,X), to znaczy:
p''(X,Y) + p''(Y,X)
p(X,Y) = ---------------------
2
Objaśnijmy bliżej istotę predefiniowanego parametru p'(X,Y) na przykładzie wykresów pojemności posiadających tylko dwa lokalne maksima. W tym przypadku oba wektory a(X) = (x_1, x_2, x_3) i a(Y) = (y_1, y_2, y_3) są wektorami w trójwymiarowej przestrzeni euklidesowej. Końce tych wektorów leżą na dwuwymiarowym równoramiennym trójkącie L, odcinającym od osi współrzędnych w przestrzeni R^3 jedną i tę samą liczbę B-A. Patrz rys.14:
 rys.14 rys.14
Jeśli odległość między punktem a(X) i punktem a(Y) oznaczymy przez |a(X)-a(Y)|, to wtedy zbiór K będzie stanowił przecięcie trójkąta L z trójwymiarowym kołem, którego środek znajdzie się w punkcie a(X), a jego promień będzie równy |a(X)-a(Y)|. W następnej kolejności trzeba podliczyć ilość „całych punktów”, tzn. punktów ze współrzędnymi całkowitoliczbowymi, w zbiorze K i w trójkącie L. Stosunek obu otrzymanych w ten sposób liczb będzie parametrem p'(X,Y).
W konkretnych obliczeniach należy posłużyć się przybliżonym sposobem wyliczenia współczynnika p(X,Y), gdyż obliczenie liczby całych punktów w zbiorze K byłoby bardzo pracochłonne. Trudność tę można jednak obejść przechodząc od „modelu dyskretnego” do „modelu ciągłego”. Dobrze wiadomo, że jeśli (n-1)-wymiarowy zbiór K w (n-1)-wymiarowym sympleksie L jest dostatecznie duży, to liczba całych punktów w K jest równa (n-1)-wymiarowej pojemności zbioru K. Dlatego też od samego początku można podstawiać pod predefiniowany współczynnik p'(X,Y) po prostu stosunek (n-1)-wymiarowej pojemności K do (n-1)-wymiarowej pojemności L.
(n-1)-wymiarowa pojemność K
p’(X,Y) = ---------------------------------------
(n-1)-wymiarowa pojemność L
Przykładowo mając dwa lokalne maksima, w miejsce współczynnika p'(X,Y) podstawiamy stosunek:
powierzchnia zbioru K
------------------------------
powierzchnia trójkąta L
Oczywiście przy małych wartościach B-A „współczynnik dyskretny” i „współczynnik ciągły” są różne. Jednak przy analizowaniu starych tekstów mamy do czynienia z okresami czasu B-A wynoszącymi kilkadziesiąt, a nawet kilkaset lat, a więc bez groźby popełnienia większego błędu spokojnie można posłużyć się „modelem ciągłym” p'(X,Y) do przeprowadzenia obliczenia wg formuł matematycznych.
Ponadto przy pracy z konkretnymi wykresami pojemności tekstów historycznych należy „wygładzać” te wykresy, zierzając do pozbycia się drobnych przypadkowych pików. Wygładzanie wykresu jest przeprowadzane przez „uśrednianie wg sąsiednich wartości”, tzn. przez zamianę wartości funkcji pojemności w każdym punkcie t na średnią arytmetyczną z trzech wartości funkcji, a mianowicie w punktach t-1, t, t+1. W miejsce „ostatecznego współczynnika” p(X,Y) należy podstawiać wartość wyliczoną dla takich właśnie „wygładzonych wykresów”. Sformułowany wyżej model korelacji maksimów potwierdzi się, jeśli dla większości par tekstów zależnych X i Y współczynnik p(X,Y) okaże się ”mały”, a dla większości par tekstów niezależnych okaże się „duży”.
EKSPERYMENTALNE POTWIERDZENIE STATYSTYCZNEGO MODELU KORELACJI LOKALNYCH MAKSIMÓW
W latach 1978-1985 przeprowadzono zakrojone na szeroką skalę eksperymentalne obliczenia parametrów p(X,Y). Efektywność opracowanych metodyk statystycznych została przebadana na dostatecznie dużym materiale źródłowym ze średniowiecznej i nowożytnej historii XVI-XX wieku, tj. na kilkudziesięciu parach konkretnych tekstów historycznych - kronik, annałów, latopisów itp.
Okazało się, że współczynnik p(X,Y) wystarczająco dobrze identyfikuje pary zależnych i niezależnych tekstów historycznych (różne epoki historyczne lub państwa). Dla tekstów niezależnych PARAMETR P(X,Y) ZAWIERA SIĘ W ZAKRESIE OD 1 DO 1/100 przy ilości lokalnych maksimów od 10 do 15. Jeśli kroniki historyczne X i Y są zależne, czyli opisują identyczne wydarzenia i potoki zdarzeń, wówczas PARAMETR P(X,Y) NIE PRZEWYŻSZA WARTOŚCI 10^-8 przy tej samej ilości lokalnych maksimów.
Jak z tego wynika, między wartością współczynnika p(X,Y) w odniesieniu do tekstów zależnych i niezależnych istnieje różnica przykładowo na 5-6 rzędów wielkości. W tym wypadku nie jest istotna absolutna wartość tego parametru, lecz fakt, że „strefa współczynników dla tekstów zależnych” różni się o kilka rzędów wielkości od „strefy współczynników dla tekstów niezależnych”.
Nota bene dla tzw. par „dynastii zależnych i niezależnych” wyliczono inne współczynniki, ale to już całkiem inna, wspomniana na wstępie, metoda. Patrz rys.15:
 rys.15 rys.15
Oto kilka przykładów przeanalizowanych tekstów:
Przykład 1
Na rysunkach 16, 17 i 18 przedstawiono wykresy pojemności dwóch zależnych tekstów historycznych.
 rys.16 rys.16
 rys.17 rys.17
 rys.18 rys.18
W miejsce tekstu X wzięto monografię historyczną współczesnego autora Władimira Siergiejewa "Очерки по истории Древнего Рима", tom 1-2, rok 1938, a w miejsce tekstu Y - „Dzieje Rzymu” Tytusa Liwiusza, tom 1-6, 1897-1899. Wg datowania tradycyjnej chronologii oba teksty opisują tę samą epokę historyczną, ten sam okres historii „antycznego” Rzymu, tj. lata 757-287 p.n.e. Wyraźnie widać, że główne piki wykresów są praktycznie równoległe. Okazało się, że parametr p(X,Y) w tym przypadku jest równy 2x10^-12. Jego mała wartość liczbowa świadczy o tym, że jeśli rozpatrujemy bliskość położenia pików na obu wykresach jako wydarzenie losowe, to prawdopodobieństwo to jest niezwykle niskie. Jak widać, współczesny autor W.Sergiejew dostatecznie dokładnie odtworzył w swej pracy „antyczny” oryginał.
Przykład 2
Analizie poddano dwa zależne teksty historyczne - kroniki ruskie:
X – Latopis Nikiforowski
Y – Kronika Supraślska
Obie kroniki opisują okres czasu jakoby 850-1256 n.e., wykresy mają po 31 pików, praktycznie równoległych i odnoszących się do tych samych lat.
 rys.19 rys.19
Wyliczenia wykazały, iż w tym przypadku współczynnik p(X,Y) = 10^-24. Jego wartość jest bardzo mała, co potwierdza zależność obu tekstów.
Przykład 3
X – Latopis Chołmogorski
Y – Powieść Minionych Lat
Okres czasu opisany w obu kronikach to jakoby 850-1000 n.e. Piki na obu wykresach osiagają lokalne maksima praktycznie jednocześnie. I znowu jest to prawidłowość, a nie absolutnie przypadkowa sytuacja, gdyż w przeciwnym razie mielibyśmy do czynienia z jedną na 10^15 szans. Współczynnik p(X,Y) jest tutaj równy 10^-15. Z porównywanych wykresów wynika, że kroniki są zależne.
 rys.20 rys.20
Na powyższym rys.20 zestawiono jednocześnie trzy wykresy dla Kroniki Supraślskiej, Latopisu Nikiforowskiego i Powieści Minionych Lat. Ostatnia z tych kronik jest „bogatsza”, jej wykres ma więcej lokalnych maksimów i choćby dlatego zależność tego tekstu nie wydaje się zbyt oczywista. Tym niemniej, po dokonaniu „wygładzenia”, okazuje się, że między trzema ww. kronikami istnieje ewidentna zależność.
Przykład 4
Przykład dotyczy średniowiecznej historii Rzymu.
X – fundamentalna monografia niemieckiego historyka Ferdynanda Adolfa Gregoroviusa „Historia średniowiecznego Rzymu”, tom 1-5. Praca ta była napisana w XIX wieku na podstawie ogromnej ilości materiałów - świeckich i kościelnych dokumentów średniowiecznych.
Y - Liber Pontificalis (T.Mommsen, Gestorum Pontificum Romanorum, 1898) – praca będąca zbiorem biografii rzymskich papieży epoki średniowiecza, napisana przez niemieckiego historyka Teodora Mommsena w XIX wieku, na podstawie średniowiecznych tekstów rzymskich. W tym przypadku okazało się, że p(X,Y)=10^-10, co wskazuje na ewidentną zależnośc obu tekstów. Dla całkiem przypadkowej bliskości pików wykresów mielibyśmy tutaj do czynienia z jedną na 10 miliardów szans.
Przykład 5
W miejsce porównywanych tekstów X i Y wzięto dwa następujące fragmenty z książki Siergiejewa "Очерки по истории Древнего Рима". Pierwszy fragment opisuje okres jakoby 520-380 p.n.e., a drugi – okres jakoby 380-240 p.n.e. Uważa się, że te okresy są niezależne. Wyliczony współczynnik p(X,Y) wynosi w tym przypadku 1/5. Jego wartość różni się o kilka rzędów wielkości od typowych wartości z zakresu od 10^-12 do 10^-6 dla tekstów zależnych, wykazujących analogiczną ilość lokalnych maksimów. Tym sposobem oba teksty, niejako dwie „połówki” pracy Siergiejewa, okazują się faktycznie niezależne.
Podczas falsyfikacji metod statystycznych porównywano:
a) stare teksty ze starymi,
b) stare teksty ze współczesnymi,
c) współczesne teksty ze współczesnymi.
Poza wykresami pojemności „rozdziałów” przetestowano także inne ilościowe charakterystyki tekstów, na przykład wykresy liczby wspominanych imion, wykresy ilości wzmianek o danym roku, wykresy częstości powołania/odesłania do jakiegoś innego istotnego tekstu itp.
Zwróćmy uwagę na jeszcze jeden ciekawy aspekt statystycznych metod analizy tekstów. Mianowicie, jeżeli dwa teksty historyczne są zależne, tzn. opisują ten sam „potok wydarzeń” w tym samym przedziale czasu historii tego samego państwa, to dla dowolnej pary przedstawionych wyżej ilościowych charakterystyk odpowiadające im wykresy wykazują piki w przybliżeniu w tych samych latach. Inaczej mówiąc, jeśli jakiś rok jest opisany w kronikach bardziej szczegółowo niż sąsiednie lata, to zwiększa się (lokalnie) liczba wzmianek o tym roku w obu kronikach, zwiększa się liczba imion postaci historycznych wspominanych w tym roku w obu kronikach itp. I odwrotnie, jeżeli teksty są niezależne, to żadnej korelacji między ww. ilościowymi charakterystykami po prostu nie ma i być nie może.
CHRONOLOGICZNE PRZESUNIĘCIA W OBRĘBIE ROSYJSKIEJ HISTORII O 300-400 LAT
Badania przeprowadzone na podstawie algorytmów statystycznych ujawniły bardzo ciekawe fenomeny w dzisiejszej historiografii.
Grupa ruskich kronik jakoby okresu 918-1098 n.e. wykazała w przybliżeniu te same wartości parametru alfa, co grupa znacznie późniejszych kronik 1330-1430 n.e. Ponadto stwierdzono, że prędkość przyrostu współczynnika alfa z upływem czasu jest w obu grupach tekstów praktycznie jednakowa. Swiadczy to o chronologicznym przesunięciu o 300-400 lat w stosunku do obowiązujących obecnie datowań.
Analogiczne zjawisko zaobserwowano także podczas porównania grup ruskich kronik jakoby z okresu 854-950 n.e. i dużo późniejszych kronik 1236-1340 n.e. i 1330-1430 n.e. Okazało się, że grupa 854-950 n.e. chronologicznie plasuje się pomiędzy grupami 1236-1340 n.e. i 1330-1430 n.e.
Porównując wartości parametru alfa absolutnie to samo obserwujemy również dla grup ruskich kronik z okresów jakoby 1110-1210 n.e. i 1500-1600 n.e.
Z powyższego wynika, że niektóre realne wydarzenia XIV-XVI wieku zostały przesunięte na osi czasu wstecz do epoki jakoby IX-XIII wieku, gdzie umieszczono DUPLIKATY tych wydarzeń.
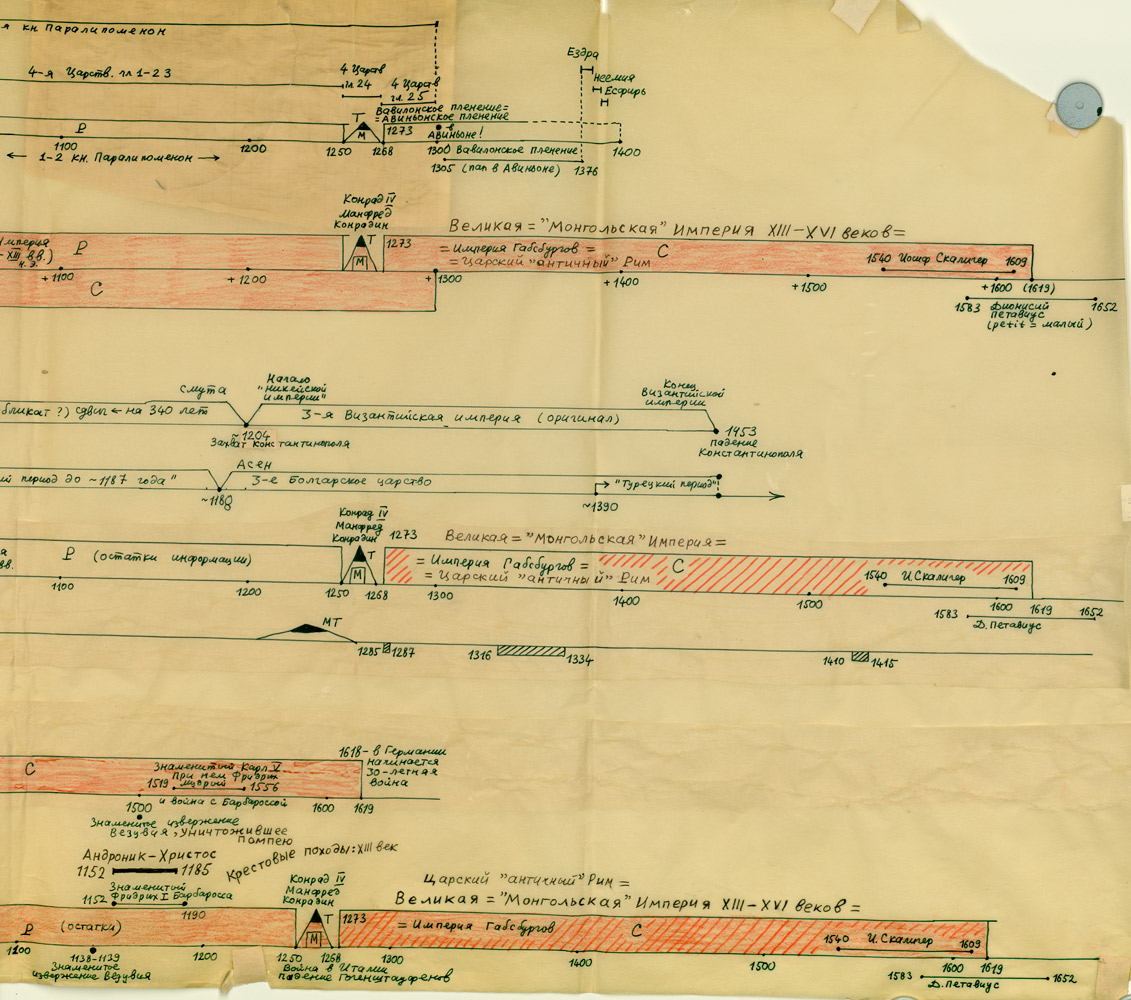
CHRONOLOGICZNE PRZESUNIĘCIA W HISTORII EUROPY I ŚWIATA O 333, 1053 I 1778 LAT
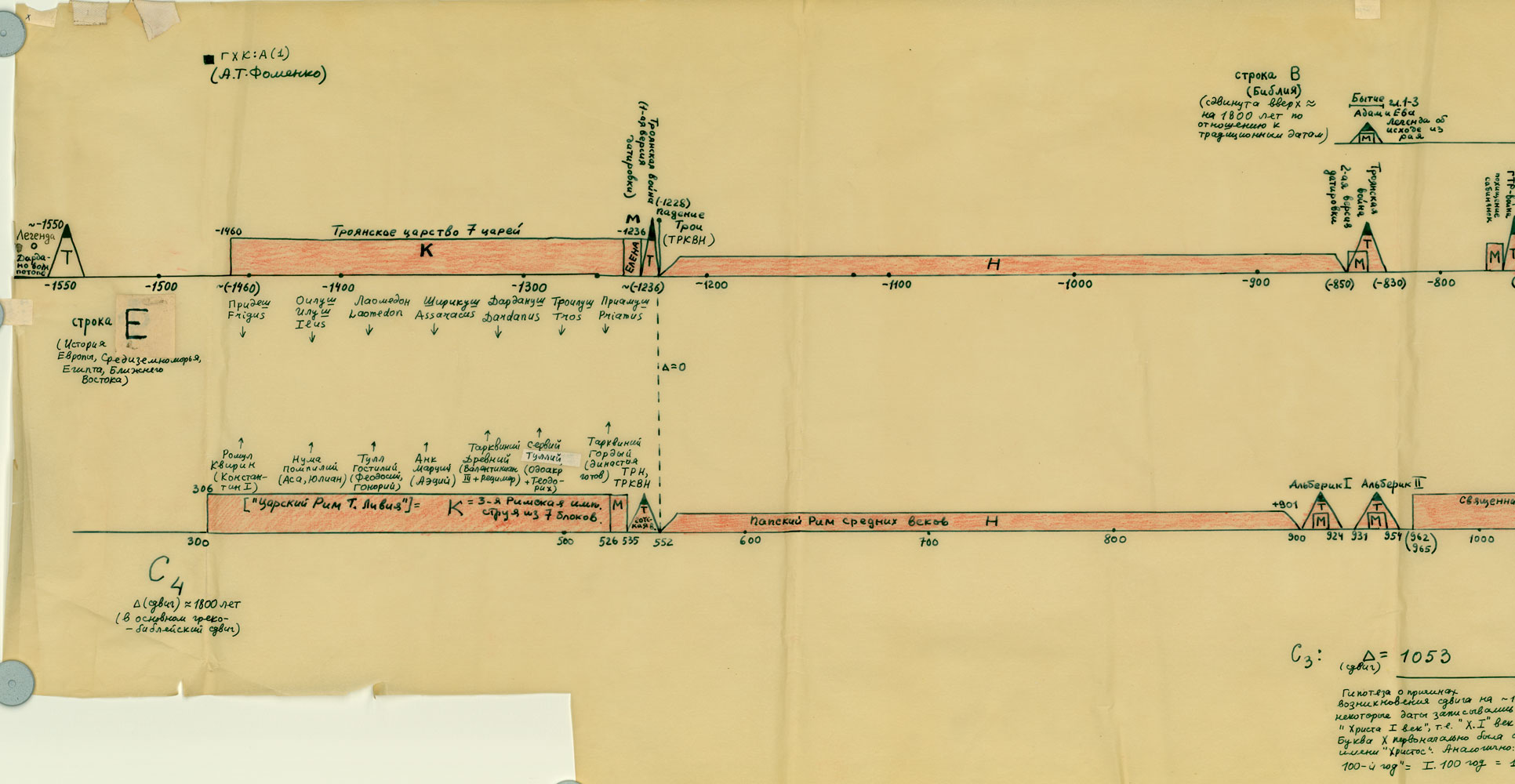
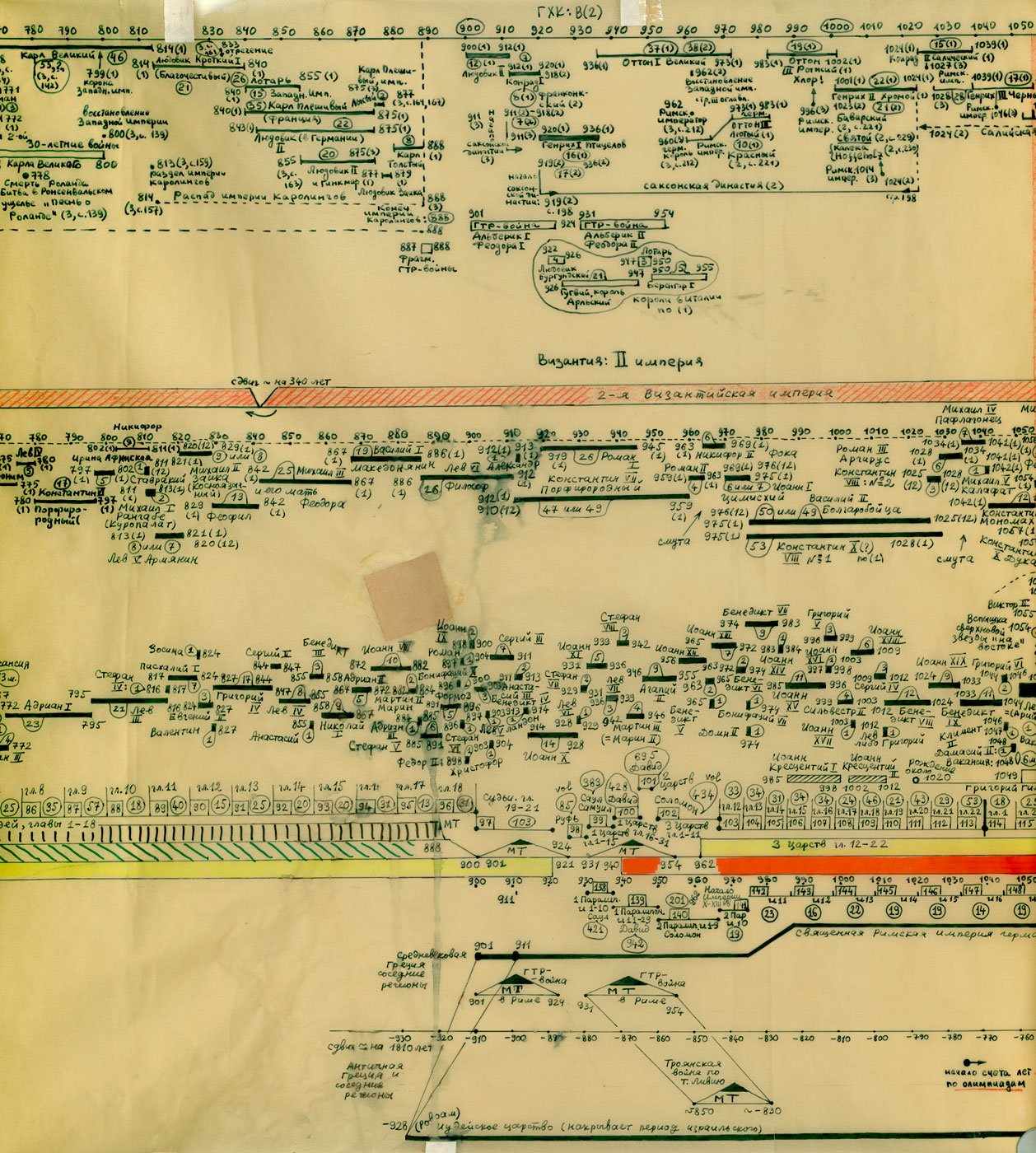
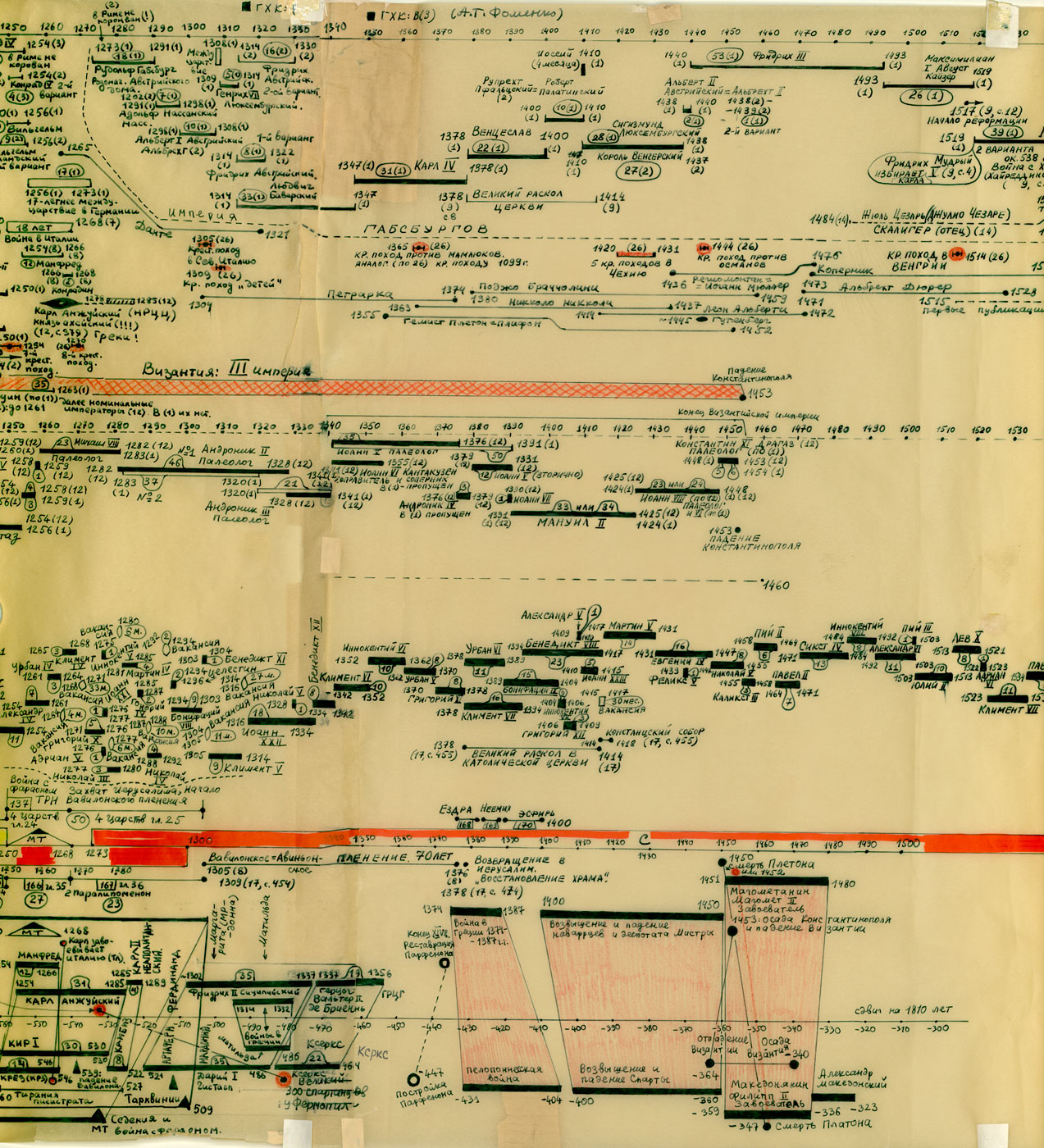
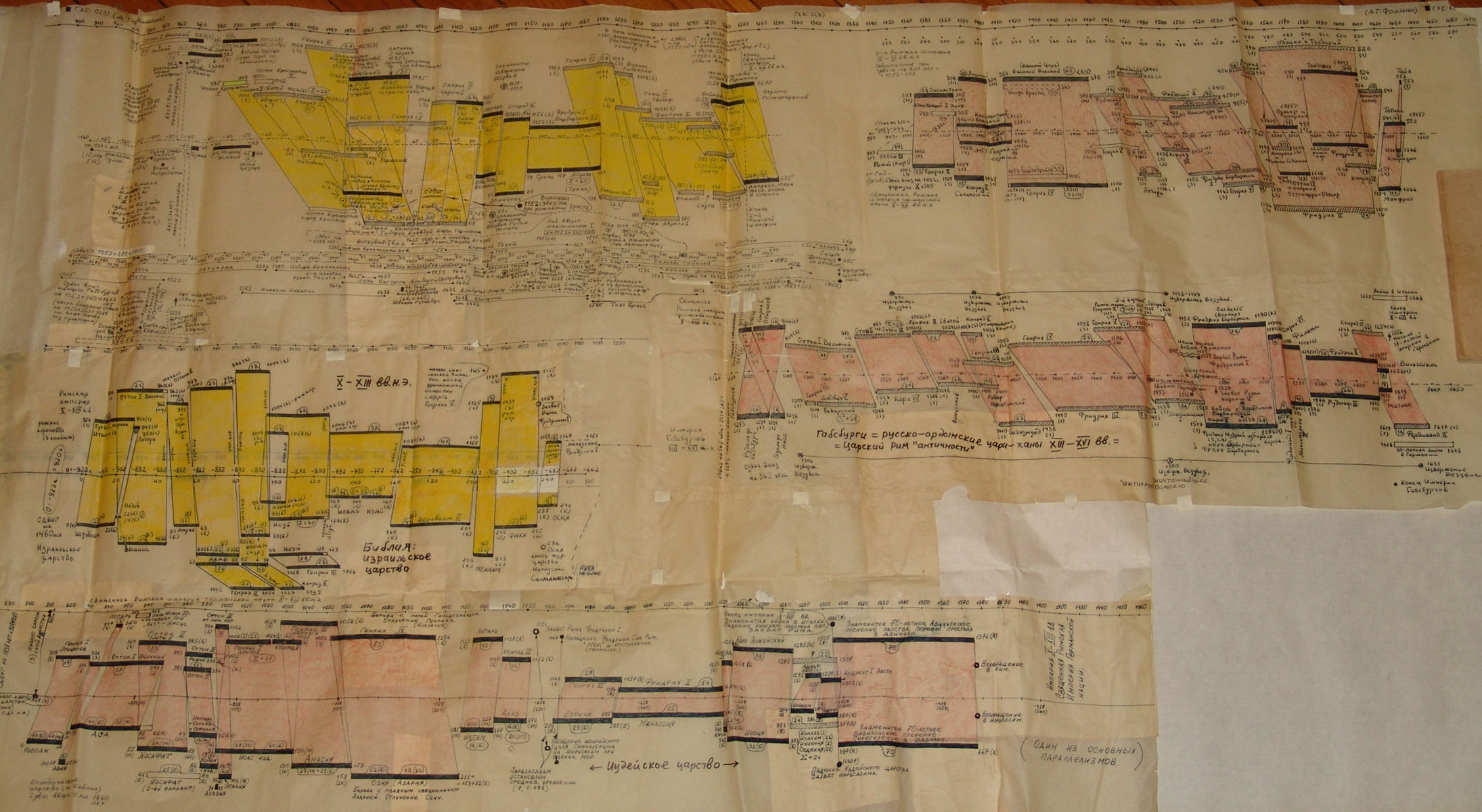
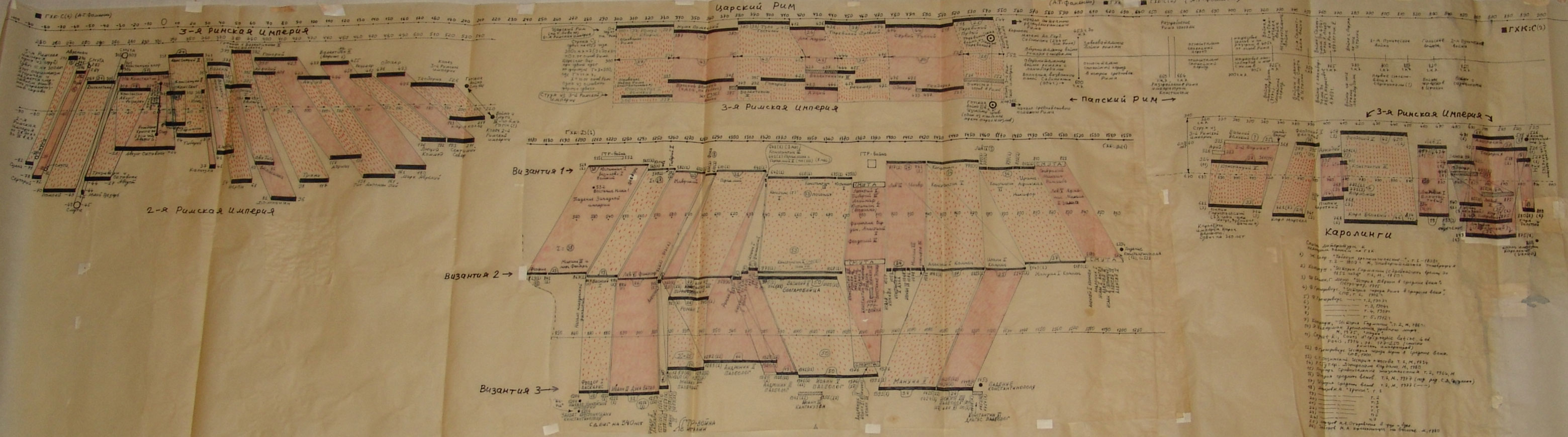
GLOBALNA MAPA CHRONOLOGICZNA
Paralelizmy w historii Europy, Bizancjum, nałożenie Biblii na historię europejską i azjatycką:
http://www.chronologia.org/gxk/im/1a.jpg
http://www.chronologia.org/gxk/im/1b.jpg
http://www.chronologia.org/gxk/im/1c.jpg
http://www.chronologia.org/gxk/im/1d.jpg
http://www.chronologia.org/gxk/im/1e.jpg
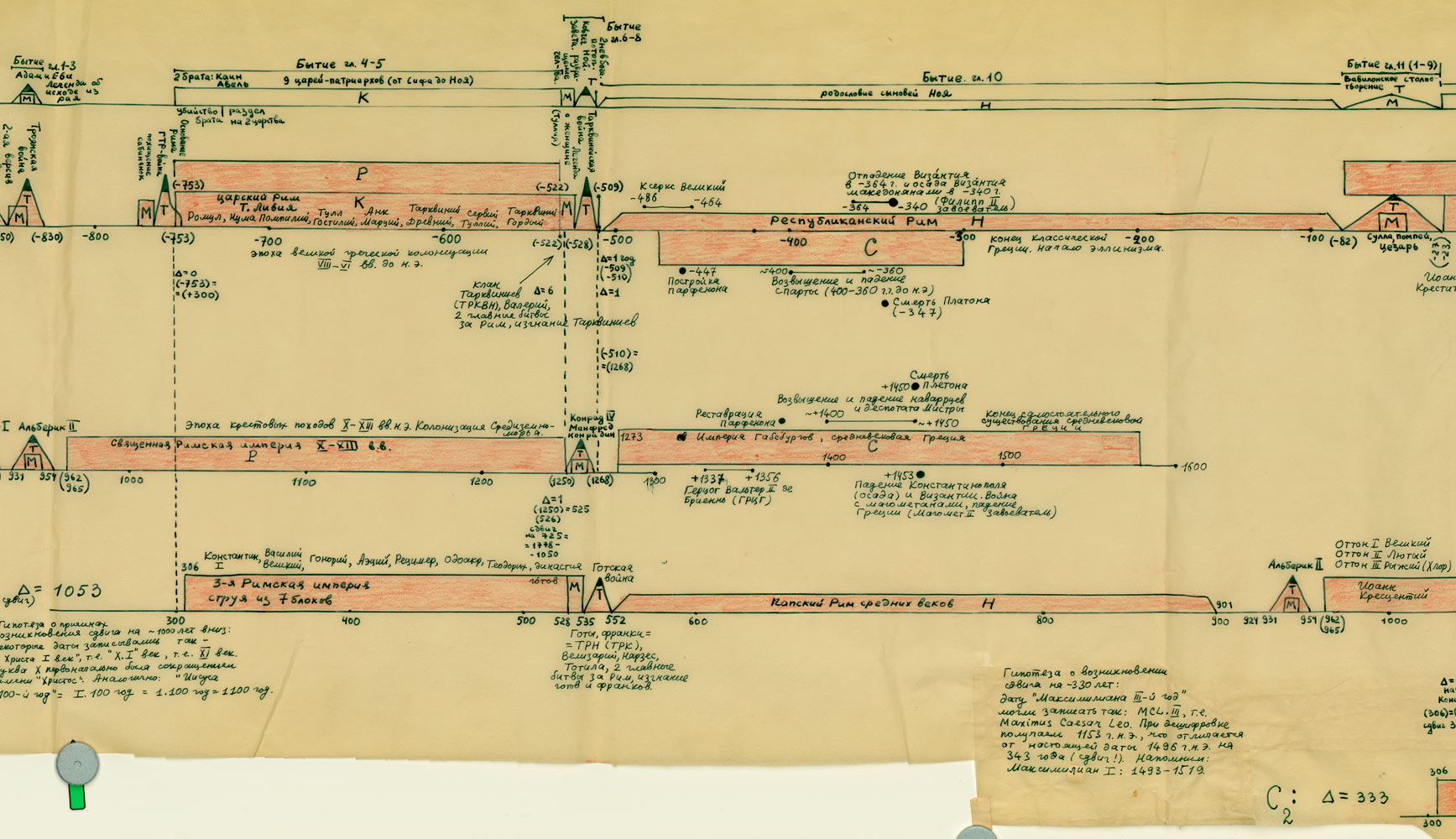
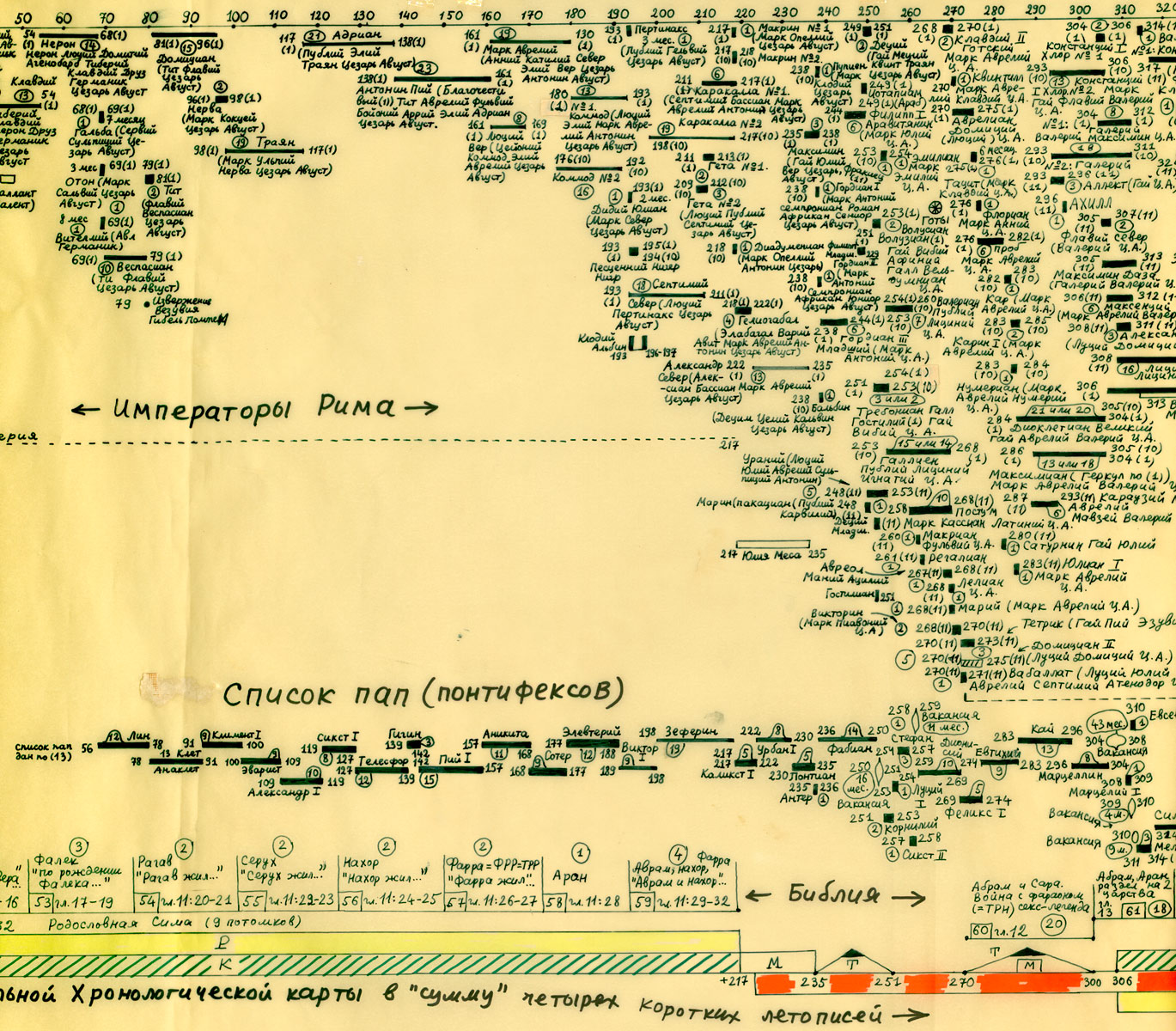
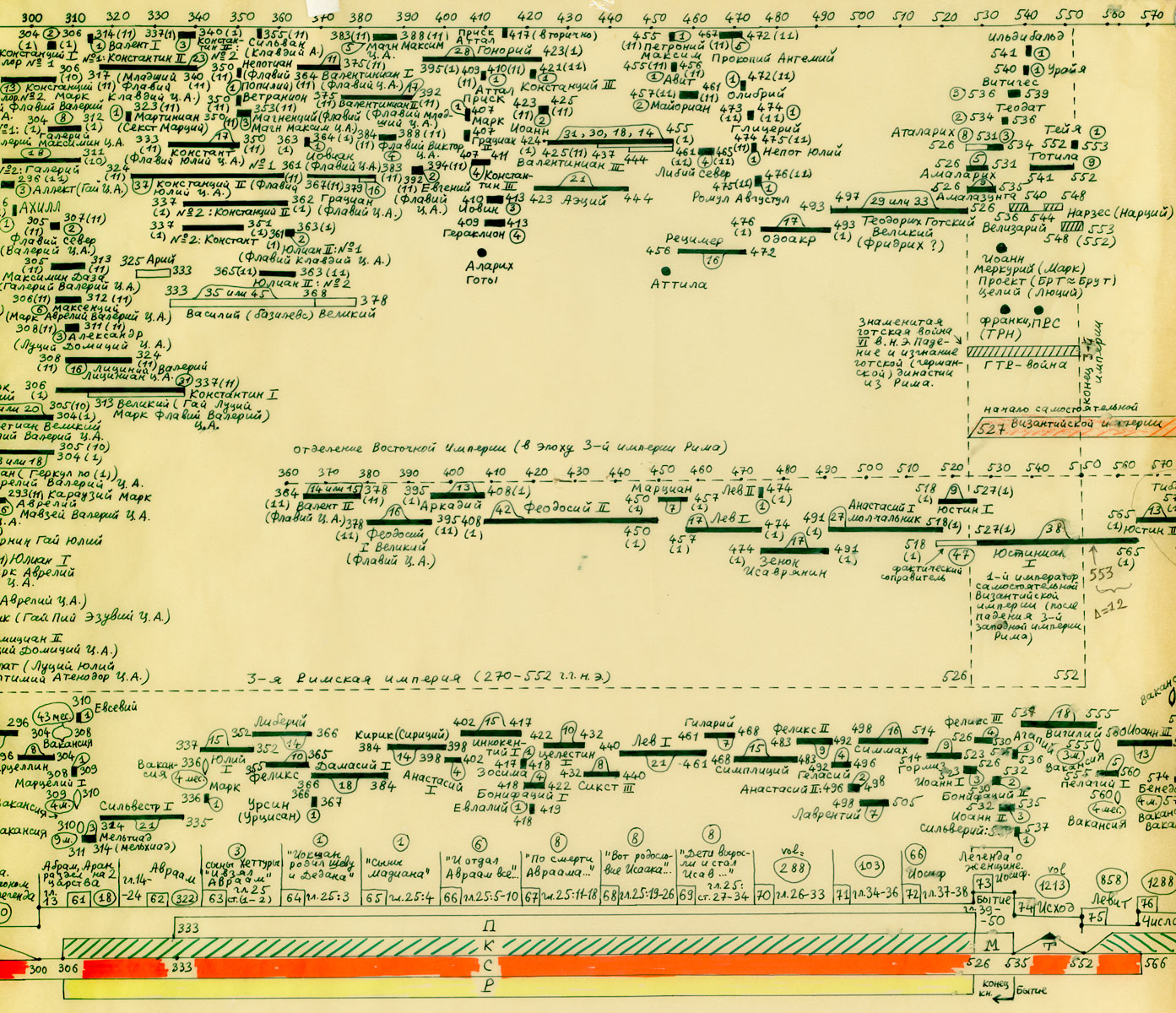
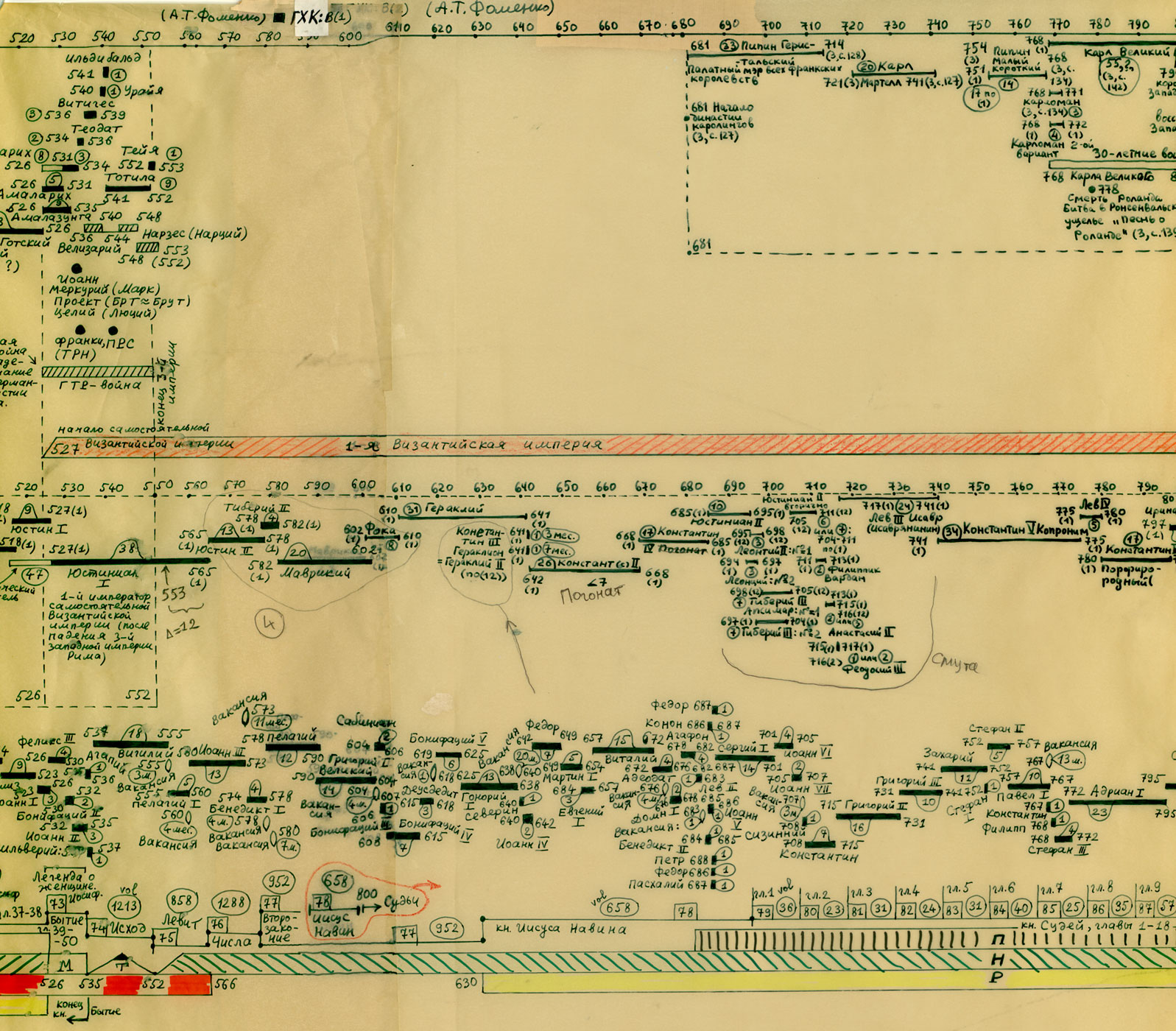
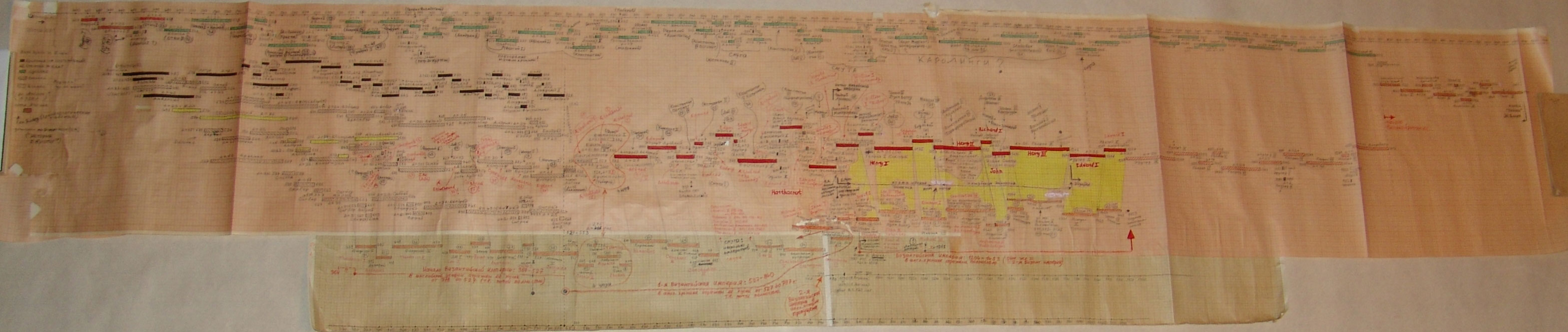
Rzym (imperatorów i pontifeksów), Bizancjum, Karolingowie, Grecja:
http://www.chronologia.org/gxk/im/2a.jpg
http://www.chronologia.org/gxk/im/2b.jpg
http://www.chronologia.org/gxk/im/2c.jpg
http://www.chronologia.org/gxk/im/2d.jpg
http://www.chronologia.org/gxk/im/2e.jpg
http://www.chronologia.org/gxk/im/2f.jpg
http://www.chronologia.org/gxk/im/2g.jpg
http://www.chronologia.org/gxk/im/2h.jpg
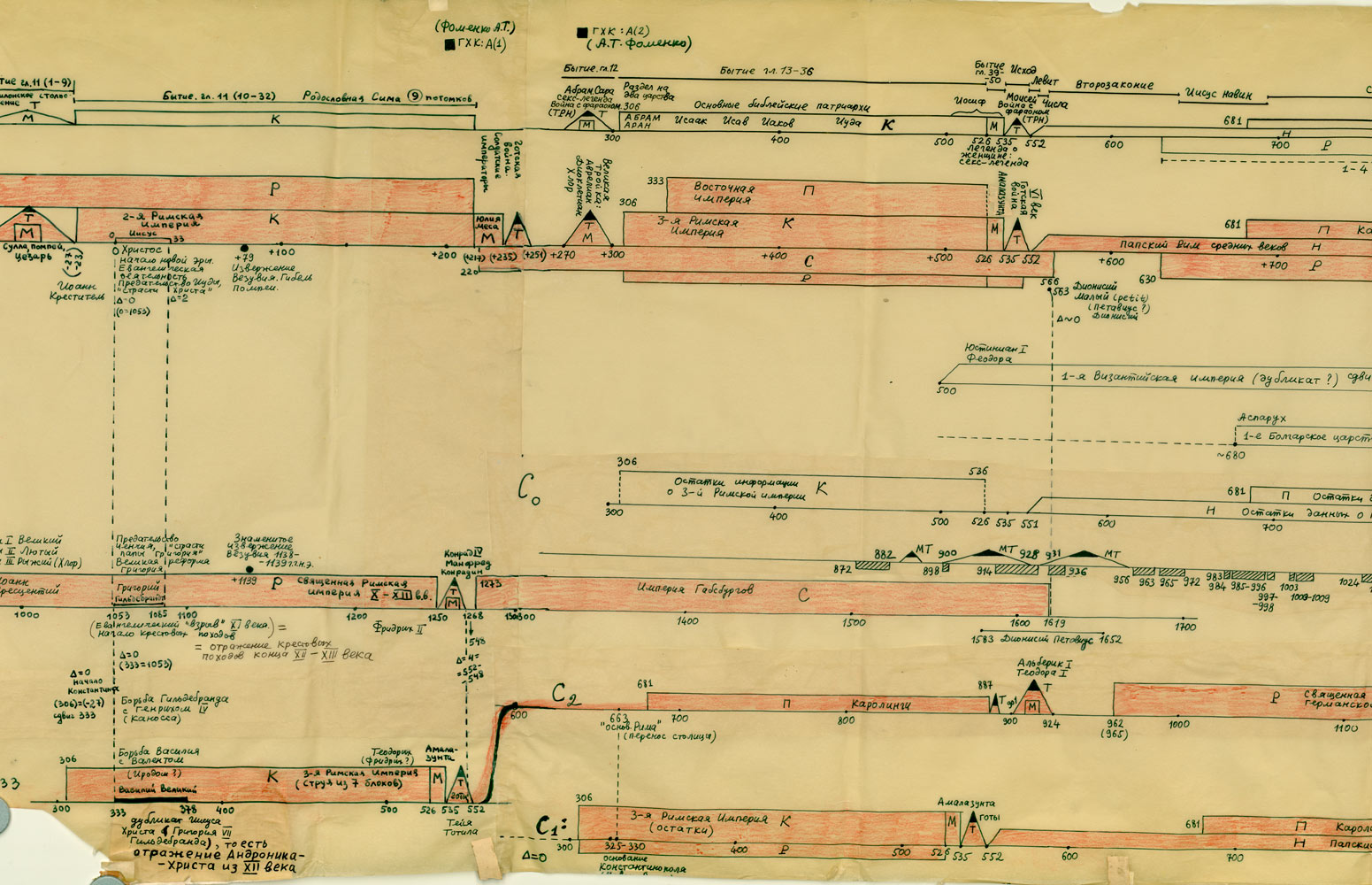
Rzym, Grecja, Habsburgowie, Biblia:
http://www.chronologia.org/gxk/im/3.jpg
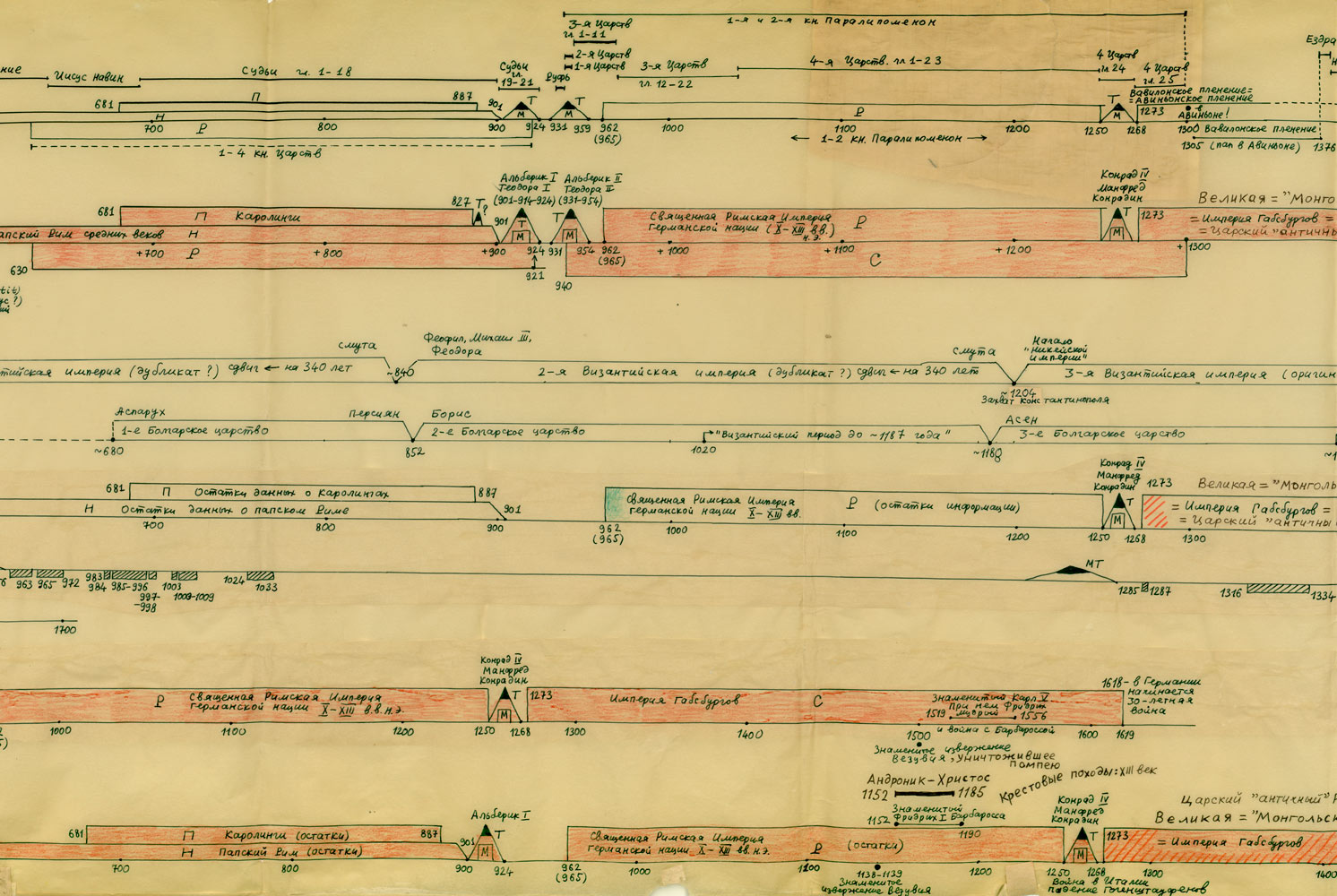
Rzym, Bizancjum, Karolingowie:
http://www.chronologia.org/gxk/im/4.jpg
Anglia, Rzym i Bizancjum:
http://www.chronologia.org/gxk/im/5.jpg
Rzym i ormiańskie katolikosy:
http://www.chronologia.org/gxk/im/6.jpg |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}